Best of show
最優秀賞
引用元:https://www.ioccc.org/2013/cable2/cable2.c
審査員・作者による説明:https://www.ioccc.org/2013/cable2/index.html
動作
手書き文字を認識するOCR。 次の画像を認識し、書かれている文字を標準出力に出す。
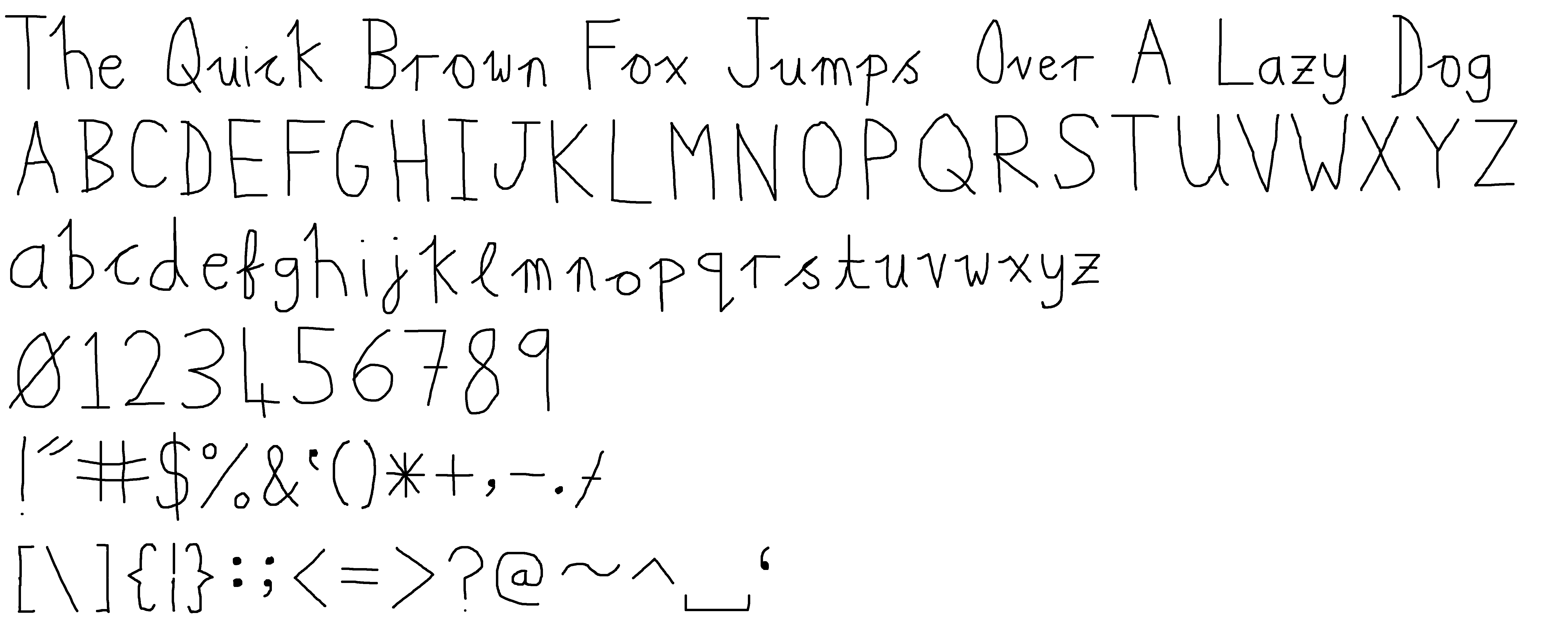
$ ./cable2 ascii.bmp
The Quick Brown Fox Jumps Over A Lazy Dog
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
0123456789
!"#$%&'()*+,-./
[\]{|}:;<=>?@~^_`
色付き文字も認識できる。
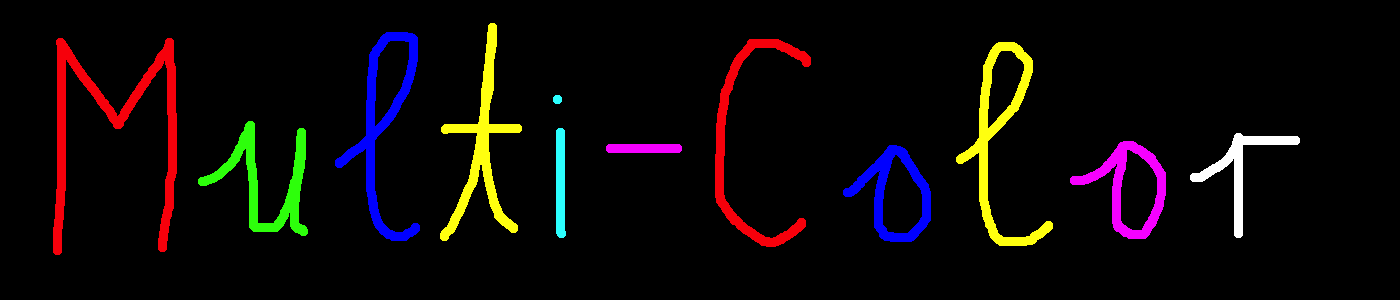
文字の大きさがバラバラでも認識できる。
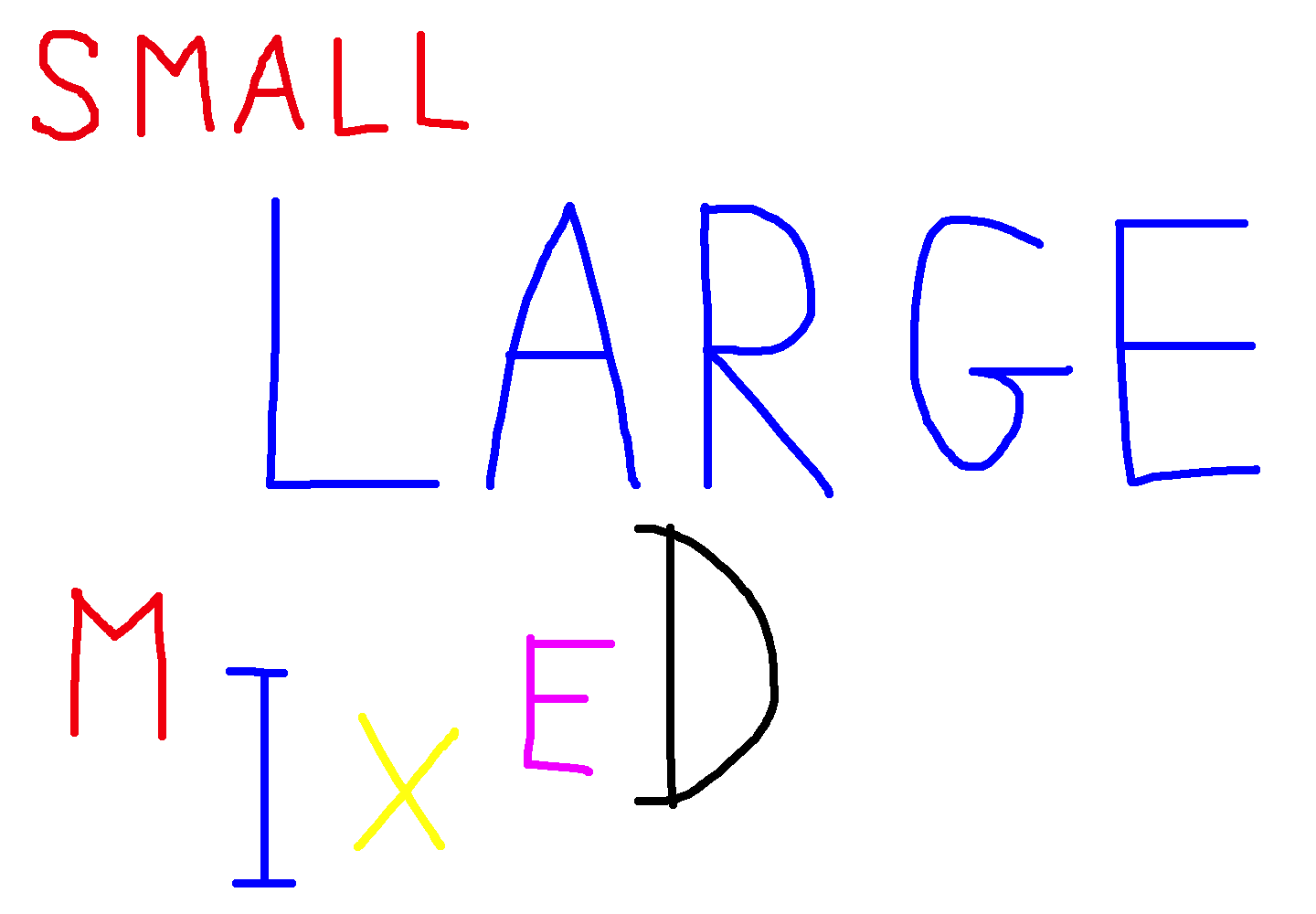
$ ./cable2 mixed_sizes.bmp
SMALL
LARGE
MIXED
手書きC言語プログラム。

$ ./cable2 hello_world.bmp | gcc -xc -o hello -
$ ./hello
Hello, world!
手書きではないフォントも、手書きフォントにある程度近ければ認識できる。

$ ./cable2 typeset.bmp
EXAMPLE OF TYPESET TEXT
IOCCC用のおまけ機能。
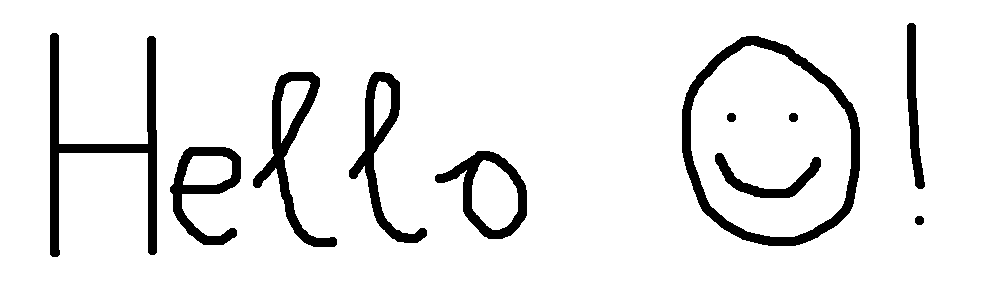
$ ./cable2 bonus.bmp
Hello IOCCC!
解説
チートではない、まじめなOCR。 bmpを受け取って、書かれた文字を認識して出力する。 特に仕込みのあるbmpではなく、自分で書いたものでよいとのこと。 横幅は4の倍数で、8ビットグレースケールか、24ビットカラーか、32ビットカラーでないとダメ。 アンチエイリアスをしても大丈夫だが、カラーモードはおかしくなることがある。
コード形状は、月と狐と犬。 フォントのサンプル文として使われるThe quick brown fox jumps over the lazy dogになぞらえたもの。 月は、なんとなく美的な雰囲気を出すためだと思う。
OCRのアルゴリズムは既存のものではなく、IOCCCのために新規開発したものとのこと。 IOCCCが独自研究のピアレビューと出版に使われた初の事例と主張している。
表示可能なASCII文字(94文字)と、空白、およびスマイルマークをサポートしている。 サイズ制限のために文字の形状はわりと限定的(ascii.bmpを参照せよとのこと)だが、拡張は可能とのこと。 文字のフォントデータは圧縮されていて、472文字。 サポートしている文字のストローク総数は約2000なので、すごい。 詳細未解析だが、いつかちゃんと解読したい。